The general research hypothesis stated that speed, accuracy, and acceptance of a multimodal, multidimensional, human-computer interface will improve when the attributes are perceptually separable, and will improve for a unimodal interface when the attributes are perceptually integral. A set of software tools was developed to simulate a prototypical biomedical data collection task in order to test the validity of this hypothesis. The experiment was designed using repeated measures, with the order of conditions counterbalanced across all subjects. The following aspects of the experiment are discussed: independent variables, dependent variables, subjects, procedure, materials, analysis, and schedule.
The two independent variables were interface (baseline, perceptually structured) and task order (slide group 1, slide group 2). The input task was to enter histopathologic observations consisting of three input attributes: topographical site, qualifier, and morphology. It was assumed that the qualifier/morphology (QM) relationship was integral, since the qualifier was used to describe or modify the morphology, such as marked inflammation. The site/qualifier (SQ) relationship was assumed to be separable, since the site identifies where in the organ the tissue was taken from, such as alveolus lung, not alveolus marked. The site/morphology (SM) relationship was assumed to be separable for the same reason. Based on these assumptions and the general research hypothesis, Table 7 predicted which modality would lead to improvements in the computer-human interface.
| Data Entry Task | Perception | Modality |
| (SQ) Enter Site and Qualifier (SM) Enter Site and Morphology (QM) Enter Qualifier and Morphology |
Separable Separable Integral |
Multimodal Multimodal Unimodal |
The three input attributes (site, qualifier, morphology) and two modalities (speech, mouse) yielded a possible eight different user interface combinations for the software prototype as shown in Table 8. Also in this table are the predicted interface improvements for entering each pair of attributes (SQ, SM, QM) identified with a "+" or "-" for a predicted increase or decrease, respectively. For testing, the third alternative was selected as the Perceptually Structured interface, because the choice of input devices was thought to best match the perceptual structure of the attributes. The fifth alternative was the Baseline interface, since the input devices least match the perceptual structure of the attributes. The third and fifth alternatives were selected over other equivalent ones, because they both required two speech inputs, one mouse input, and the two speech inputs appeared adjacent to each other on the computer screen.
| Modality | Site | Qual | Morph | SQ | SM | QM | Interface |
| 1. Mouse 2. Speech 3. Both 4. Both 5. Both 6. Both 7. Both 8. Both |
M S M S S M S M |
M S S M S M M S |
M S S M M S S M |
- - + + - - + + |
- - + + + + - - |
+ + + + - - - - |
Perceptually Structured Baseline |
The dependent variables for the experiment were speed, accuracy, and acceptance. The first two were quantitative measures while the latter was subjective.
Speed was recorded both by the experimenter and the software prototype. It was defined as the time it takes a participant to complete each of the 12 data entry tasks and was recorded to the nearest millisecond. The actual speed was determined by analysis of timing output from the prototype, recorded observations of the experimenter, and review of audio tapes recorded during the study.
Three measures of accuracy were recorded both by the experimenter and the software prototype: speech errors, mouse errors, and diagnosis errors. Speech recognition errors were counted when the prototype incorrectly recognized a spoken utterance by the participant. This was either because the participant was misunderstood by the prototype or the participant spoke a phrase that was not in the vocabulary. Mouse errors were recorded when a participant accidentally selected an incorrect term from one of the lists displayed on the computer screen and later changed his or her mind. Diagnosis errors were identified as when the input of a participant did not match the most likely diagnosis for each tissue slide. The actual number of errors was determined by analysis of diagnostic output from the prototype, recorded observations of the experimenter, and review of audio tapes recorded during the study.
User acceptance data was collected using a subjective questionnaire containing 13 bi-polar adjective pairs which has been used in other human computer interaction studies [Casali, Williges, and Dryden 1990; Dillon 1995]. The adjectives are listed in Table 9 and the actual survey can be found in the Appendices in Section 6.3. The questionnaire was given to each participant after testing was completed. An acceptability index (AI) was defined as the mean of the scale responses, where the higher the value, the lower the user acceptance.
|
slow inaccurate inconsistent irritating undependable unnatural incomplete uncomfortable unfriendly distracting complicated useless unacceptable |
Twenty subjects from among the biomedical community participated in this experiment as unpaid volunteers between January and February 1997. Each participant reviewed 12 tissue slides, resulting in a total of 240 tasks for which data was collected. The target population was veterinary and clinical pathologists, graduate students and post-doctorates from the Baltimore-Washington area. Since the main objective was to evaluate different user interfaces, participants did not need a high level of expertise in animal toxicology studies, but only to be familiar with tissue types and reactions. The participants came from the University of Maryland Medical Center (Baltimore, MD), the Baltimore Veteran Affairs Medical Center (Baltimore, MD), the Johns Hopkins Medical Institutions (Baltimore, MD), the Food and Drug Administration Center for Veterinary Medicine (Rockville, MD), and the Food and Drug Administration Center for Drug Evaluation and Research (Gaithersburg, MD). To increase the likelihood of participation, testing took place at the subjects' facilities.
The 20 participants were distributed demographically as shown in Table 10, based on responses to the pre-experiment questionnaire found in the Appendices in Section 6.1. The sample population consisted of professionals with advanced degrees, ranged in age from 33 to 51 years old, and were roughly equal in the number of males and females. Fifteen were from an academic institution, and most were U.S. born, native English speakers. The majority indicated they were comfortable using a computer with all but 3 ranking themselves with a 4 or higher in computer and mouse experience. Only 1 subject had any significant speech recognition experience.
| Highest Degree Institution Age Gender National Origin Native Language Computer Experience Mouse Experience Speech Experience |
D.V.M. 11 JHMI 8 Mean 40 Male 11 US 13 English 16 Mean 5 Mean 5 Mean 1 |
Ph.D. 6 UMMC 7 Stdev 6.8 Female 9 Europe 4 Other 4 Stdev 1.1 Stdev 1.5 Stdev 0.9 |
M.D. 3 BVAMC 3 India 2 |
FDA 2 Canada 1 |
The subjects were randomly assigned to the experiment using a within-group design. Half of the subjects were assigned to the perceptually-structured-interface-first, baseline-interface-second group and were asked to complete six data entry tasks using the perceptually structured interface and then complete six tasks using the baseline interface. The other half of the subjects were assigned to the baseline-interface-first, perceptually-structured-interface-second group and completed the tasks in the reverse order.
Also counterbalanced were the tissue slides examined. The slides came from the National Center for Toxicological Research (Jefferson, AK). Two groups of six slides with roughly equivalent difficulty were randomly assigned to the participants. This resulted in 4 groups based on interface and slide order as shown in Table 11. For example, subjects in group BIP2 used the baseline interface with slides 1 through 6 followed by the perceptually structured interface with slides 7 through 12. The actual slide diagnoses are shown in Table 12.
| Group | Interface Order | Slide Order |
| B1P2 B2P1 P1B2 P2B1 |
Baseline, Perceptually Structured Baseline, Perceptually Structured Perceptually Structured, Baseline Perceptually Structured, Baseline |
1-6, 7-12 7-12, 1-6 1-6, 7-12 7-12, 1-6 |
Repeated measures (a within-groups design) is common among human computer interaction studies evaluating two or more input devices or other interface characteristics [Karl, Pettey, and Shneiderman 1992; Margono and Shneiderman 1993; Sears and Shneiderman 1991; Oviatt 1996]. Repeated observations on the same subject over time is a more efficient use of resources, since less participants are needed. Also, the estimation of time trends is more precise, because measurements on the same subject tend to be less variable than measurements on different subjects [Keul 1994].
| Group | Slide | Diagnosis (Organ, Site, Qualifier, Morphology) |
| 1 2 |
1 2 3 4 5 6 7 8 9 10 11 12 |
Ovary, Media, Focal, Giant Cell Ovary, Follicle, Focal, Luteoma Ovary, Media, Multifocal, Granulosa Cell Tumor Urinary Bladder, Wall, Diffuse, Squamous Cell Carcinoma Urinary Bladder, Epithelium, Focal, Transitional Cell Carcinoma Urinary Bladder, Transitional Epithelium, Focal, Hyperplasia Adrenal Gland, Medulla, Focal, Pheochromocytoma Adrenal Gland, Cortex, Focal, Carcinoma Pituitary, Pars Distalis, Focal, Cyst Liver, Lobules, Diffuse, Vacuolization Cytoplasmic Liver, Parenchyma, Focal, Hemangiosarcoma Liver, Parenchyma, Focal, Hepatocelluar Carcinoma |
Each subject was tested individually in a laboratory setting at the participant's place of employment or study. Participants were first asked to fill out the pre-experiment questionnaire found in the Appendices in Section 6.1. The subjects were told that the objective of this study was to evaluate several user interfaces in the context of collecting histopathology data and was being used to fulfill certain requirements in the Ph.D. Program of the Computer Science and Electrical Engineering Department at the University of Maryland Baltimore County. They were told that a computer program would project images of tissue slides on a computer monitor while they enter observations in the form of topographical sites, qualifiers, and morphologies.
After reviewing the stated objectives, each participant was seated in front of the computer and had the head-set adjusted properly and comfortably, being careful to place the microphone directly in front of the mouth, about an inch away. Since the system was speaker-independent, there was no need to enroll or train the speech recognizer. However, a training program was run, to allow participants to practice speaking typical phrases in such a way that the speech recognizer could understand. The objective was to become familiar speaking these phrases with reasonable recognition accuracy. Participants were encouraged to speak as clearly and as normally as possible.
Next, each subject went through a training session with the actual test program to practice reading slides and entering observations. Participants were instructed that this was not a test and to feel free to ask the experimenter about any questions they might have.
The last step before the actual test was to review the two sets of tissue slides. The goal was to make sure participants were comfortable reading the slides before the test. This was done to help ensure the experiment was measuring data input and not the ability of the subjects to read slides. During the review, participants were encouraged to ask questions about possible diagnoses.
For the actual test, participants entered two groups of six histopathologic observations in an order based on the group they were randomly assigned to. They were encouraged to work at a normal pace that was comfortable for them and to ask questions before the actual test began. After the test, the user acceptance survey was administered as a post-experiment questionnaire. A summary of the experimental procedure can be found in Table 13.
| Step | Task |
| 1 2 3 4 5 6 |
Pre-experiment questionnaire and instructions Speech training Application training Slide review Evaluation and quantitative data collection Post-experiment questionnaire and subjective data collection |
A prototype computer program was developed for the experiment using Microsoft Windows 3.11 (Microsoft Corporation, Redmond, WA) and Borland C++ 4.51 (Borland International, Inc., Scotts Valley, CA). Some software components from the preliminary study described earlier were used in this effort. About 1,500 lines of code were written for two software programs. The first, pe_test, supported the speech training task and the second, sm_test, was used for the evaluation and data collection task.
The PE500+ was used for speech recognition (Speech Systems, Inc, Boulder, CO). The hardware came on a half-sized, 16-bit ISA card along with head-mounted microphone and speaker, and accompanying software development tools. Software to drive the PE500+ was written in C++ with the SPOT application programming interface. The Voice Match Tool Kit was used for grammar development. The environment supported speaker-independent, continuous recognition of large vocabularies, constrained by grammar rules.
The software and speech recognition hardware were deployed on a portable PC-III computer with a 12.1 inch, 800x600 TFT color display, a PCI Pentium-200 motherboard, 32 MB RAM, and 2.5 GB disk drive (PC Portable Manufacture, South El Monte, CA). This provided a platform that could accept ISA cards and was portable enough to take to the participants' facilities for testing.
The main data entry task for the experiment was for subjects to view microscopic tissue slides and enter histopathologic observations. To minimize hands-busy or eyes-busy bias, no microscopy was involved. Instead, the software projected images of tissue slides on the computer monitor while participants entered observations in the form of topographical sites, qualifiers, and morphologies. The software provided prompts and directions to identify which modality was to be used for which inputs. A sample screen is shown in Figure 2.
The default operating mode for the PE500+ speech recognizer is called push-to-speak. In the push-to-speak mode, the user holds down a mouse button or foot pedal when speaking, so the recognizer knows when to process incoming utterances. The push-to-speak mode tended to have a higher recognition accuracy rate, but needed to be avoided so as not to introduce additional effects into the experiment. Therefore, a software driver was developed that allowed the recognizer to operate in a voice-activated mode. Here, the PE500+ is always listening for speech input. Instead of having the user press and release a button, the start and end of an utterance was determined by signal amplitude levels, length of signal, and length of silence.
Basic assumptions about the distribution of data were used to perform the statistical analysis. The Central Limit Theorem states that for a normal population with mean and standard deviation , the sample mean observed during data collection is normally distributed with mean and standard deviation / n1/2, provided the number of observations n in the sample is sufficiently large and the sample mean is genuinely unbiased by the random allocation of conditions [Noether 1976]. Several null hypotheses were derived from the general research hypothesis stating that there was no difference between the subject groups (i.e, that the experimental manipulation did not effect the results). Testing each null hypothesis was done by computing the probability of obtaining that result. If the probability indicates that the result did not occur simply by chance, then the null hypothesis could be safely rejected [Johnson 1992].
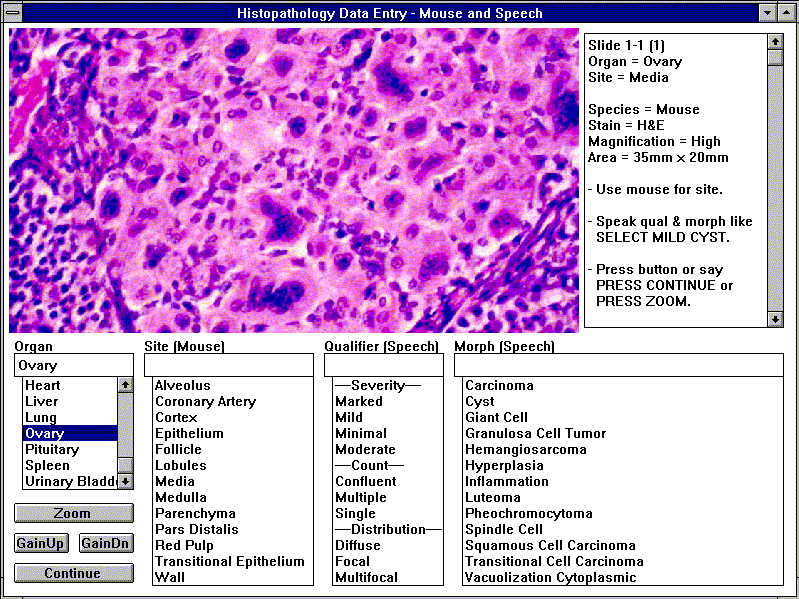
Figure 2: Sample Data Entry Screen
As stated earlier, a within-groups experiment, fully counterbalanced on input modality and slide order was performed. The data collected consisted of pairs of measurements taken on the same subjects, with the results analyzed as a single sample of differences. The F test and t test were used to determine if different samples came from the same population, for example, the baseline-interface-first and the baseline-interface-second groups. Finally, regression analysis was used to identify relationships between any of the dependent variables.
The success of these research objectives was demonstrated by completing and delivering the following items. The deliverables and work schedule are shown in Table 14 and Table 15. The schedule is based on a one-year effort, broken into three major parts: planning, operation, and interpretation [Basili 1986]. Included in experiment setup is a pilot study to evaluate the experimental procedures on a limited number of subjects. This allowed for changes to the experiment without biasing the pool of test subjects.
| Task | Duration |
| Experiment design and software development Pilot study Retooling Experiment operation Analysis of results and publication development |
2 months 1 month 1 month 4 months 4 months |
| Deliverables |
| The software prototype evaluated in the study Data gathered from user testing (written, tape recorded, or video taped) A Ph.D. Dissertation covering this effort in detail One or more reports or publications based on this research |