This chapter contains a review of literature regarding this research effort. Related work in multimodal interfaces using direct manipulation and speech recognition is covered. An overview of research concerning key reference attributes and interface tasks is included. Motivations for the application of speech interfaces in the biomedical area are presented. Background information on the target application of data collection in animal toxicology studies is given. The chapter concludes with an outline of preliminary work in biomedical speech interfaces.
Several research efforts have attempted to develop multimodal interfaces using direct manipulation and speech recognition. Three of these are described below. While each has a different area of emphasis, all three are feasibility studies centered around the development and testing of a multimodal interface to demonstrate proof-of-concept. In their conclusions, they all call for empirical evaluations to refine and evaluate these interface techniques.
Two approaches to multimodal interfaces are presented - synergistic and integrated. Both are shown graphically in Figure 1. In a synergistic interface, each modality can perform the same set of tasks. No new functionality is added to the interface, except that the user can select the input device which is most convenient at any given time. One example of this is navigation under Microsoft Windows, where either the mouse or the keyboard can be used to switch to the other windows. In contrast to this, an integrated interface is different in that there are certain tasks which can only be carried out by using both input devices together. The advantage here is that the functionality of the interface is extended with integrated tasks like "point-and-speak."
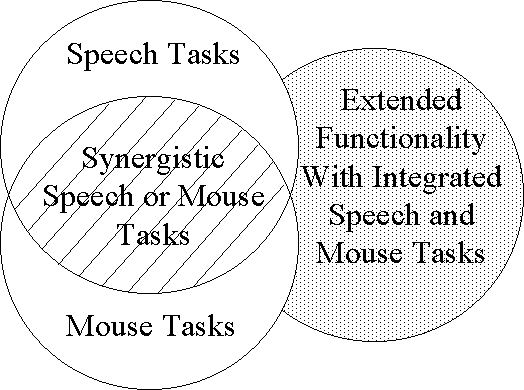
Figure 1: Synergistic versus Integrated Interface Tasks
One effort at the Oregon Graduate Institute sought to evaluate spoken language as an alternative interface to multimedia applications [House 1995]. Specifically, a multimodal interface to the World-Wide Web [CERN] was developed. The basic architecture of the system was a remote recognition-capable Web server with speech recognition software and speech-capable HTML (Hypertext Markup Language) documents. The local Web browser was extended to digitize the user's utterances and send them to the server for speech recognition and processing.
It was noted that, while the mouse-based interface can be credited with much of the popularity of the Web, there are inherent limitations. These limitations focus on difficulty in performing complex commands and access to documents that cannot be reached by a visible link. The latter - access to non-visible references - was the focus of their effort, and was motivated by the framework for complementary behavior between natural language and direct manipulation suggested by Cohen [1992].
Speech and direct manipulation were both used to develop an interface with a synergistic interaction style that allowed either modality to perform the same set of tasks [Lefebvre, Duncan, and Poirier 1993]. The user could then select the input device that best suits the task at hand. Speech recognition and direct manipulation were used as complementary modalities. As a result, speech input was believed to allow access to information that was not directly available with mouse-based systems, such as navigating to HTML links that were not visible.
The main advantage of using speech is that all references are potentially available, even when they are not visible. One question not raised was the need for predictability when selecting non-visible references. For example, will users have a difficult time selecting a non-visible reference if they do not know, or cannot predict, what those references are? This may be especially true with the World-Wide Web, as users navigate through unfamiliar documents searching for information.
Another difficulty is the use of multiple labels like "Click here," which can result in reference ambiguity. In addition, the use of Postscript, and other presentation-based encodings which assume a single display format, limit the ability to use speech output on the Web [Ramon 1995]. These factors highlight the need to enforce document development guidelines [Conte 1994] before speech-driven Web access can become commonplace.
An alternative approach is to use natural language and direct manipulation to develop what has been called an integrated user interface. In one such effort, Cohen [1992] attempted to not simply provide two or more separate modalities with the same functionality, but to integrate them to produce a more productive interface. For example, along with traditional unimodal operations like "point-and-click," there can be integrated ones like "point-and-speak." The guiding principle in this research was to use the strengths of one modality to overcome the weaknesses of the other.
For simplicity, the term "natural language" was used independent of the transmission medium - keyboard, speech, or handwriting. Even though meaningful differences exist between spoken, keyboard, and written interaction [Oviatt and Cohen 1991; Kassel 1995], those differences were not germane to the key point about modality integration. Note also that this dissertation deals with speech recognition, not natural language, both of which have distinct characteristics [Shneiderman 1980]. However, there is enough overlap between the two for this research to provide relevant background material.
Based on this objective, a prototype multimodal system was developed using an integrated direct manipulation and natural language interface. Several examples were cited where the combination of language and mouse input together were thought to be more productive than either modality alone. For example, natural language allowed the use of anaphoric references (pronouns). However, the exact meaning of these references can be ambiguous. Following Webber's arguments [1986], the prototype used icons to explicitly display what it believed the valid references were, given the current context. The combination of anaphoric reference with pointing used the unambiguous nature of pointing to overcome this error-prone aspect of natural language processing.
A second example of integration introduced by Cohen was with the use of time. One might assume that direct manipulation would be better than speech for dealing with time by using a slider bar as a graphical rendition of a time line. However, this is not always the case. Finding timed events with a slider can be an extremely slow linear search process, especially if there is a large range of time intervals to scan. If the granularity of the slider is too large, selecting the exact time event may not be possible. Also, sliders typically allow the selection of only one time point. To overcome these limitations, the prototype used natural language to describe the times of interest. The prototype then composed a menu of all time points selected with the slider set to the first one found. Here, natural language was used to overcome a weakness in direct manipulation - the selection of unknown objects (in this case, time points) from a large set.
Using the mouse to disambiguate the context of speech input has also been explored by the Boeing Company [Salisbury et al. 1990]. Their motivation was that human communication is multidimensional and that conversations include more than just spoken words. The combination of graphics and verbal data to complete or disambiguate the other was termed "talk and draw." Within this framework, operators would input requests by speaking commands while simultaneously selecting graphical objects with a mouse to determine the context of these commands.
A project at the Massachusetts Institute of Technology used speech as an auxiliary channel to support window navigation [Schmandt, Ackerman, and Hindus 1990]. Xspeak provided a speech interface to X Windows by allowing navigational tasks usually performed with a mouse to be controlled by speech instead. The effort was developed with the assumption that speech input is more valuable when it is combined with other input devices and that most successful speech recognition systems have small vocabularies, are speaker-dependent, and use discrete speech.
The X Windows system uses a spatial metaphor to organize applications on a monitor in three dimensions. However, it uses a two-dimensional device for window navigation, namely the mouse. When there are many overlapping windows, it can be difficult to reach some applications directly with the mouse. Xspeak was therefore designed to improve navigation in this type of environment. Each window is associated with a voice template. When the word represented by a template is spoken, the window is moved to the foreground and the mouse pointer is moved to the middle of the window. Window navigation can be viewed as a hands-busy task. Using Xspeak, users can manage a number of windows without removing their hands from the keyboard.
Initial testing revealed that while speech was not faster than the mouse for simple change-of-focus tasks, the advantage shifted toward speech if the desired window was partly or completely hidden. Another observation was that the users most inclined to choose speech input increased the number of overlapping windows or the degree of overlap.
The following section discusses how reference visibility, reference number, and reference predictability can affect the performance of speech interfaces.
It has been suggested that speech input is better than mouse input when selecting non-visible references. However, due to the fleeting nature of spoken words, the impact of non-visible references on the cognitive costs of the user must be considered. For example, the less feedback or prompting a program provides, the more a user has to remember, and the more performance may suffer. The following studies suggest that the lack of visible references has a negative cognitive impact on both speech and direct manipulation interfaces.
An experiment was conducted at the University of Maryland College Park to demonstrate the utility of speech input for command activation during word processing [Karl, Pettey, and Shneiderman 1992]. It was believed that speech would be superior to the mouse with respect to the activation of commands. Also, word processing was considered a hands-busy, eyes-busy application, since the user would have to interrupt typing of text in order to execute word processing commands. Speech-activated commands were found to be faster than mouse-activated commands and to have similar error rates. Speech showed the greatest advantages during command-intensive tasks as opposed to typing-intensive tasks.
One unexpected result was that subjects made significantly more memorization errors when using speech. For one of the tasks, not all of the information could be displayed on the screen at one time. This meant that the participants had to memorize symbols and page up and down while using speech-activated commands. The researchers observed a less-than-expected performance increase for this task using speech. When questioning the users, at least half noted that it was harder to memorize and recall descriptions when using voice input. Memorization problems did not interfere with mouse users performing the same task. This finding might explain why the use of graphics to display the visual context in which the various grammatical rules applied was shown to improve the speed and accuracy of speech recognition [Wulfman et al. 1993].
Another study observed increased cognitive requirements while retrieving hidden information with a mouse [Wright, Lickorish, and Milroy 1994]. To conserve space, a common practice is to remove information from computer displays that readers will only need intermittently. This information is often accessible by a single mouse click. The study demonstrated that this practice impairs one's memory for other task components due to increased cognitive costs. These findings suggest that software should be designed with additional memory support for users with small screens and also help to explain the success of icon bars and ribbon displays which give people immediate access to the functions they frequently use.
A related study empirically evaluated the effect of various user-interface characteristics on data entry performance for clinical data [Poon and Fagan 1994]. The characteristics tested were 1) displaying results as one long scrolling list or as a series of pages, 2) using dynamic palettes which pop-up when needed and are customized to the particular data collection event or fixed palettes, and 3) showing all findings or just those which are relevant in the current context.
Intuitively, one can argue that the use of scrolling, dynamic palettes, and showing relevant results allows for greater flexibility and better management of screen space. However, all three had a negative impact on performance due to increased memory requirements on the user. The study found that paging, fixed palettes, and showing all results provided better performance. With these characteristics, users could memorize the screen position of various objects and the need for commands to explicitly invoke or dismiss dynamic palettes was eliminated. Also, by showing all results, not just relevant ones, users were more confident of their findings and spent less time with follow-up questions.
The use of scrolling, dynamic palettes, and relevant findings resulted in a user interface with more variation than their counterparts. This, in turn, increased the cognitive costs on the user and decreased performance. A similar conclusion was reached by Mitchell and Shneiderman [1989]. This effort set out to show that dynamic or adaptive menus would perform better than fixed menus. Instead, they discovered that frequent changes to the menu order have a negative effect on users. They concluded that stability and predictability in menus was the preferred approach.
It has been suggested that the more references there are (or the larger the vocabulary), the better suited an application may be to speech recognition [Cohen and Oviatt 1994]. While this might be the case, there seems to be little evidence to support this. Consider the task of selecting an item out of a list, or a 1-out-of-N task. For small lists, Welch [1997] showed that the entry of numbers using a keyboard is faster and less error prone than entry by speech. This was later confirmed by Damper [1993].
In contrast to this, increasing vocabulary size had an interesting effect in the synergistic multimodal window navigation project described earlier [Schmandt, Ackerman, and Hindus 1990]. When there were fewer windows, the mouse performed better than speech. However, the more windows there were (or the larger the vocabulary), the more speech outperformed direct manipulation. There is another reference attribute to consider other than the size of the vocabulary or the lack of visibility. Note that increasing the number of references did not adversely affect the performance of the speech interface. However, since each window was given a name by the user, there should also have been a high degree of predictability within the vocabulary.
Dillon evaluated the effect of vocabulary size among nurses during a hands-busy data entry task. He showed that a larger inclusive vocabulary can lead to far fewer non-recognized phrases [Dillon, Norcio, DeHaemer 1993]. Although one vocabulary was larger than the other, both were functionally equivalent. The larger vocabulary contained alternative word choices while the smaller one used a minimal set. With both vocabularies, the user still had the same number of functional tasks to consider. This suggests that broadening a vocabulary to accommodate alternative phrases should increase the performance of a speech interface. However, it does not imply that increasing vocabulary size by adding functionality of a vocabulary will do the same.
An area of growing interest is to identify the best ways to integrate speech into multimodal environments. Research here includes those conditions where people are likely to integrate two input modalities as well as what advantages can be leveraged. Two such efforts are presented. The first studied how the perceptual structure of the input attributes can affect the performance of multidimensional input tasks. An overview on the perception of structure is given as background material. The second examines those conditions under which a person is likely to combine two modalities.
In this section, it is important to understand the difference between "integral" and "integrated," since they sound similar but have different connotations. The term, "integral," is used in the theory of perceptual structure to characterize the relationship between the dimensions of a structure as indivisible. This can refer to the structure of an input device or an input task. The term, "integrate" is used to describe the combining of two modalities and using them in concert.
Structures abound in the real world and are used by people to perceive and process information. Structure can be defined as the way the constituent parts are arranged to give something its peculiar nature. It is not limited to shape or other physical stimuli, but is an abstract property transcending any particular stimulus. Information and structure are essentially the same in that they are the property of a stimulus which is perceived and processed.
Perception occurs in the head, somewhere between the observable stimulus and response. Perception consists of various kinds of processing that have distinct costs, so the response is not just a simple representation of the stimulus. By understanding and capitalizing on the underlying structure, it is believed that a perceptual system could reduce these costs and gain advantages in speech and accuracy.
Garner documented that the dimensions of a structure can be characterized as integral or separable and that this relationship may affect performance under certain conditions [Garner 1974; Garner and Felfoldy 1970]. The dimensions of a structure are integral if they cannot be attended to individually, one at a time; otherwise, they are separable.
A structured system is one that contains redundancy. The following examples illustrate that the principle of redundancy is pervasive in the world around us. A crude, but somewhat useful method for weather forecasting is that the weather today is a good predictor of the weather tomorrow. An instruction cache can increase computer performance because the address of the last memory fetch is a good predictor of the address of the next fetch. Consider a visual picture on a video screen. The adjacent pixels are usually similar to each other. Without this structure, the video screen would be perceived as meaningless noise or snow.
The next two examples are from Pomerantz and Lockhead [1991]. Consider two sequences: XOXOXOXOXO and OXXXOOXOXO. Each has five Xs and five Os and each is equally likely to occur from the 1,024 possible patterns. Yet the first pattern is considered better than the second, because of inferred subsets. The first pattern has fewer inferred alternatives than the second because it is perceived as more regular and predictable than the second. The goodness of a pattern is correlated with redundancy. Good stimuli are perceived as being in small subsets. The more redundancy, the smaller the subset. Given two subsets, each created from different total sets of the same size, if one subset is smaller, it has more redundancy. Also, by observing a single stimuli, we may be able to infer what the subset is. For example, given the letter E, one may infer the subset included letters of the alphabet.
There are two ways to introduce structure into a system. One is to present the stimuli in a nonrandom order, such as repeating a sequence of five circles in the same order. The other is to correlate the dimensions of a structure, such as an increase in circle size corresponding to an increase in its color or lightness.
The introduction of structure can improve performance, as shown by the following example. Consider a set of five circles that vary in size, and a set of twenty-five circles that vary in size and lightness. The one-dimensional circles are a 1 x 5 set while the two-dimensional circles are a 5 x 5 set. The 1 x 5 set should have performance advantages, due to its smaller size. However, by adding structure, this advantage is eliminated. Structure can be added by correlating the two attributes of the 5 x 5 set. In this arrangement, an increase in size corresponds to an increase in lightness for each of the five sizes. The result is that the 5 x 5 set would now have only five valid choices, just like the 1 x 5 set.
Speech and the mouse as input devices have significantly different control structures. The following study suggests that this can have a measurable impact on performance based on whether the control structure of each device matches the perceptual structure of the input task. Therefore any consideration of the advantages of one modality over the other should take into account these differences.
In this study, the researchers tested the hypothesis that performance improves when the perceptual structure of the task matches the control structure of the input device [Jacob et al. 1994]. A two-dimensional mouse and a three-dimensional tracker were used as input devices. Two input tasks with three inputs each were used, one where the inputs were integral (x location, y location, and size) and the other where the inputs were separable (x location, y location, and color). Common sense might say that a three-dimensional tracker is a logical superset of a two-dimensional mouse and therefore is always as good and sometimes better than a mouse. Instead, the results showed that the tracker performed better when the three inputs were perceptually integral, while the mouse performed better when the three inputs were separable.
The theory of perceptual structures, integral and separable, was originally developed by Garner [1974]. The structure has to do with how the dimensions of the input task combine perceptually. This theory was extended with the hypothesis that the perceptual structure (or how these dimensions are perceived) of an input task is key to the performance of multidimensional input devices on multidimensional tasks.
Consider the graphical input tasks in Table 4. Both use three attributes. However, Garner [1974] has shown that the attributes of the first graphical task are integral. That is, all three dimensions are in the same perceptual space. With the other graphical task, the three attributes are in separate perceptual spaces. This effort focused on multidimensional input on unimodal input devices. For multimodal environments, an appropriate follow-on question is the effect of integral and separable tasks using two or more input modalities in concert. Along with the graphical tasks, Table 4 contains integral and separable tasks from the biomedical application domain used in this dissertation.
| Domain | Task Type | Input Attributes |
| Graphical Biomedical |
Integral Separable Integral Separable |
Location and size of a screen object Location and color of a screen object Qualifier and morphology (marked inflammation) Site and qualifier (follicle marked) |
A number of related studies were performed to examine how people might integrate input from different devices in a multimodal computer interface. The first study used a simulated service transaction system with verbal, temporal, and computational input tasks using both structured and unstructured interactions [Oviatt and Olsen 1994]. Participants were free to use either handwriting, speech, or both during testing. The following results were reported. As shown in Table 5, digits were more likely written than text, proper names were more likely written than other textual content, and structured interactions were more likely written than unstructured interactions.
| Task | Written | Spoken |
| Verbal/Temporal Verbal/Temporal & Computational Textual Textual & Computational Proper Names Structured Unstructured |
13.0% 18.0% 9.7% 14.7% 21.5% 6.9% 18.9% |
87.0% 82.0% 90.3% 85.3% 78.5% 93.1% 81.1% |
The most significant factor in predicting the use of integrated multimodal speech and handwriting was contrastive functionality. Here, the two modalities were used in a contrastive way to designate a shift in context or functionality, such as original input versus corrected, data versus command, digits versus text, or digits and referring description. Of all the transactions using writing and speech, 57% were due to one of the contrastive patterns identified in Table 6. Also shown in Table 6 is the tendency toward certain combinations, such as written data and spoken command versus spoken data with written command.
| Task | Occurrence |
| Written Input and Spoken Correction Spoken Input and Written Correction Written Data and Spoken Command Spoken Data and Written Command Spoken Text and Written Digits Written Text and Spoken Digits |
50% 50% 73% 27% 85% 15% |
A related study examined the use of spoken and written input while interacting with an interactive map system [Oviatt 1996]. Input modality (speech, writing, multimodal) and map display format (structured, unstructured) were manipulated in a simulated environment to measure performance errors, spontaneous disfluencies, and task completion time. With the previous study predicting users would prefer multimodal to unimodal interfaces, this study explored whether there were performance advantages as well. A simulated service transaction system was used by participants to assist with map-based tasks.
The study revealed that increased length of spoken utterances and unstructured displays resulted in more disfluencies. Speech-only input also resulted in more performance errors and increased task completion time. Participants revealed a preference to using speech and writing for complementary functions. This was backed up by quantitative data showing the greatest speed advantages of multimodal input that used pen-based pointing and gestures to identify location and speech for other data input.
The two key points in this section on multimodal input tasks are the positive relationship of contrastive functionality to multimodal interaction and the application of the theory of perceptual structures to multidimensional, unimodal input tasks. These findings were used to develop the dissertation hypothesis that multidimensional, multimodal input tasks will exhibit increased speed, accuracy, and acceptance when the input attributes are perceived separable. When the attributes are integral, unimodal input would be more beneficial.
Automated speech recognition can address two key concerns in human-computer interaction: the demand for ease of use and constraints on the user's ability to work with the keyboard or mouse. The technology is still limited, however, with most successful systems using small to medium-size vocabularies with well-defined grammar rules. In the area of medical informatics, the main applications of speech recognition systems described in the literature are for 1) template-based reporting, 2) natural language processing, 3) multimodal integration of speech with other methods of input, and 4) data entry in hands-busy environments. The first two reflect the need for more intuitive interfaces. The latter two deal with limitations of traditional input using the keyboard or mouse.
Template-based reporting systems have been used in radiology, pathology, endoscopy, and emergency medicine. They have large vocabularies, recognize discrete speech, and are speakeradaptive systems designed to generate template-based reports using fillin forms, trigger phrases, and free-form speech. Turnaround time is decreased and accuracy is increased by eliminating the need for dictation and transcription by clerical personnel.
Reaction to this approach has been mixed. For autopsy pathology, it was noted that a greater degree of computer literacy is required and that the need for typed input is not eliminated [Klatt 1991]. When applied to endoscopy, the process took longer than standard dictation and nevertheless collected less information [Massey, Geenen, and Hogan 1991]. These problems were attributed to the fact that therapeutic endoscopic procedures are complex and not suited to a template-based reporting format. The free-form speech method, in which single words are printed as they are spoken, was found to be too slow to be useful [Dershaw 1988]. This was probably due to increased computational requirements associated with larger vocabularies (up to 40,000 words). On the positive side, the formality of the process seemed to provide other benefits. One researcher noted that 80% of emergency room reports were adequately completed with a speech recognition system, as compared with 30% when reports were dictated or handwritten records were used [Hollbrook 1992].
A group at Stanford University studied the use of speech as an improved interface for medical systems. Initial work focused on the development of three prototype speech-driven interfaces [Issacs et al. 1993] along with research on how clinicians would like to speak to a medical decision-support system [Wulfman et al. 1993]. It was noted that the use of template-based dictation with fill-in forms worked well only when the documentation task was limited to a few standardized reports. Template-based reporting may be inadequate in clinical domains, because the required documentation is less standardized. At the same time, current speech recognition technology does not permit the processing of free-form natural language. Methods that circumvent shortcomings in the current technology while maintaining the flexibility and naturalness of speech are being explored.
Three prototype systems were developed that were more complex linguistically than template-based reporting, and the typical entries could not easily be selected from a simple presentation of menus. The systems had a speaker-independent vocabulary of more than 38,000 words using continuous speech. In addition, Windows-based graphics were used as control and feedback mechanisms for the various grammatical rules in the system. This use of graphics to display the visual context in which the various grammatical rules applied was shown to improve the speed and accuracy of recognition except when the grammar was complex. Overall, the evidence suggests that graphical guidance can be used effectively when the vocabulary is sufficiently constrained.
A different approach for speech recognition is to develop multimodal systems that use speech in combination with other input devices. The goal in this case is not to replace the keyboard or mouse but to simplify or accelerate the input process. One such system, designed to assist in the collection of stereological data, combined speech input with a digitizing pad [McMillan and Harris 1990]. Each data set consisted of an object name recorded by voice, followed by X and Y coordinates entered with a digitizing pad. The system was used for boundary analysis and histomorphometry of bone and skin. It had a small speaker-dependent vocabulary (less than 50 words) for object names and voice commands, and recognized discrete speech. The system allowed a user to choose between a small set of control words and about 20 object names. The combination of speech and a digitizing pad was shown to accelerate the data collection process.
Several efforts used a speech-driven approach to facilitate the collection of data in a hands-busy environment. This has been a key motivation for the application of speech in the medical area as well as in other domains. Hands and eyes-busy data collection was also the principal motivation behind the preliminary work described below.
One study examined the feasibility of using speech recognition to record clinical data during dental examinations [Feldman and Stevens 1990]. Systems of this type would eliminate the need for a dental assistant to record results. Speech input was shown to be slower. However, when the time needed to transfer results recorded by the dental assistant into the computer was considered, the speech method was considered faster. Speech input also had more errors, although the difference was not statistically significant. Overall, the study suggested that speech recognition may be a viable alternative to traditional charting methods.
Another effort designed a speech interface for an anesthetist's record keeping system [Smith et al. 1990]. Anesthetists are responsible for recording information on drugs administered during medical procedures. Due to hands-busy limitations, a long interval typically exists between an event and its recording, which can compromise the completeness and accuracy of the manual record. By using speech input, this data can be collected during the medical procedure, while the anesthetist's hands are busy. The system used a vocabulary of around 300 words. Preliminary testing showed an accuracy rate of 96%, even in a noisy operating room.
Hands-busy data collection has also been applied to the analysis of bone scintigraphic data [Ikerira et al. 1990]. Such diagrams are analyzed to study metastases of malignant tumors. A speech system was developed to allow doctors to enter the results of image readings into the computer while looking at the images instead of the terminal. In 580 voice-entered reports, response time was shortened in comparison with dictation or writing by hand.
Data entry has become the bottleneck of many scientific applications designed to collect and manage information related to experimental studies. In animal toxicology studies, this is true because of the need to collect data in hands-busy or eyes-busy environments. For example, during microscopy, the operator's hands and eyes are occupied with the process of examining tissue slides. During necropsy, gross observations and organ weights must be collected while the operator's hands are busy and soiled. With in-life data collection, technicians record daily observations while handling animals. An ancillary data collection issue is that it may not be practical to keep computer equipment in animal rooms and laboratories, where it is most convenient to record observations.
Large volumes of pathology data are processed during animal toxicology studies. These studies are used to evaluate the long-term, low-dose effects of potentially toxic substances, including carcinogens. This information must be collected, managed, and analyzed according to Good Laboratory Practice regulations for animal studies [U.S. FDA 1978]. Since the 1970's, several systems have been developed to automate this process [Cranmer et al. 1978; Faccini and Naylor 1979]. Procedures for manual data entry were set up. Others included interfaces to clinical chemistry and hematology analyzers to automate data collection [Daly et al. 1989]. Today, however, the collection of microscopic, gross, and in-life observations is still a limiting factor, due to hands-busy and eyes-busy restrictions.
Several software systems have been developed in this area, such as the Toxicology Data Management System (NCTR, Jefferson, AK), Starpath (Graham Labs, San Antonio, TX), and Labcat (Innovative Programming Associates, Princeton, NJ). These and other applications deal with specific information management and analysis issues. However, automation at the source of data collection through speech recognition has yet to be fully explored. Speech is a natural means of communication that would address the data entry bottlenecks which can occur with standard data collection processes. The highly structured and moderately sized vocabulary (as opposed to freeform and large vocabulary) required by these applications can easily be supported by current speech recognition systems. Automating at the source of data collection has the potential to greatly reduce transcription and data validation costs that consume 25 to 33 percent of the total cost of bringing new drugs to market [Green 1993].
Preliminary work by the author in this area includes a feasibility study of voice-driven data collection [Grasso and Grasso 1994]. The objective was to determine the feasibility of using voice recognition technology to enable hands-free and eyes-free collection of data related to animal toxicology studies. A prototype system was developed to facilitate the collection of histopathology data using only speech input and computer-generated speech responses. After testing the prototype system, the results were evaluated to determine the feasibility of this approach and provide a basis for implementing voice-driven systems that support microscopic, gross, and in-life data collection.
The hardware for this study consisted of an IBM-compatible 486/33 computer with Microsoft Windows 3.1 (Redmond, WA). Software was developed under Microsoft Windows using Borland C++ 3.1 and the Borland Object Windows Library 1.0 (Borland International, Inc., Scotts Valley, CA). Watcom SQL for Windows 3.1 (Watcom International Corporation, Waterloo, Ontario, Canada) was the relational database chosen. The Verbex 6000 AT31 Model 0637 Voice Input Module with 3 megabytes of memory, 40 MHz processor, and text-to-speech synthesis was used for voice recognition and computer-generated voice responses (Verbex Voice Systems, Inc., Edison, NJ).
Two separate interfaces were developed for data collection. One used the keyboard, mouse and computer monitor with standard interface objects such as dialog boxes, push buttons, and pulldown menus. The other used only speech input and computer-generated speech responses with no visual feedback. Note that these were two distinct user interfaces and that speech-driven capabilities were not merely added to the Windows user interface. Simply adding speech to an existing user interface has been shown to decrease system integrity or cause integration discontinuity [Wulfman et al. 1988].
The grammar was a continuous-speech, speaker-dependent vocabulary of 900 words, based on the Pathology Code Table [1985]. The list of possible words and phrases was divided into functional subsets for navigation, voice response, error correction, nomenclature terms, and data collection.
An informal series of four tests was conducted. In each test, the subject was either a pathology assistant, medical technologist or software engineer. The first test was to train the system to recognize each user's voice by reading each word twice, followed by reading representative words in context.
The second test was used to validate the accuracy of the voice recognition system apart from the application. Each user was asked to read a series of 100 randomly generated phrases. The number of correctly recognized phrases was used to compute the recognition accuracy. If a phrase was accidentally read incorrectly, it was not counted as an error, and the user was given a second chance to read the phrase again. Invariably, users needed to repeat the training for specific words that the system was not recognizing consistently. If retraining was successful, these were not counted as errors.
In the next test, each user was asked to navigate to various animals and enter several microscopic observations. Here, voice recognition was not used. Instead, the keyboard and mouse were used for input and a computer monitor for visual responses. This test was to allow the users to familiarize themselves with the environment and provide a comparison for data entry using voice input.
The final test required each user again to navigate to various animals and enter several microscopic observations. This time, however, the mouse, keyboard, and monitor could not be used. Instead, each user relied on voice input and computergenerated voice output.
Overhead associated with training was a limiting factor. Roughly four to eight hours were required for each user to train on the entire vocabulary of 900 terms. The mean recognition rate was 97% in the accuracy test. In the last test, most participants felt uncomfortable at first when entering observations without any visual feedback. This was due in part to difficulty in understanding computer-generated speech. After a few practice runs, they were entering data without assistance. However, many felt the system should provide more feedback during data collection - be it visual or audible. The mean recognition rate in this test was also 97%. These accuracy rates were determined under controlled conditions, so they should be viewed as a best-case scenario.
The initial training requirements are a potential hindrance to the acceptance of a system of this type. In a time when few people, if any, read the user's guide, it is difficult to envision a pathologist spending hours training the system to recognize his or her voice. An alternative that warrants further study is a speaker adaptive approach. Here, instead of training the system, operators would use a set of generic voice recognition templates, which would automatically be adapted for each person with continued use.
Another interesting observation has to do with word conflicts in the vocabulary. Such conflicts can occur with short, similar sounding words like "tree" and "three". It was initially believed that a vocabulary of complex medical terms would be immune to such problems. However, there were some conflicts with phrases like "inferior vena cava" and "superior vena cava".
The area of computer feedback requires additional research. Since the system operated in an eyes-busy environment, there could be no visual computer feedback. Several areas were anticipated where audible confirmation would be appropriate, such as when a word was recognized by the system or when an observation was saved in the database. However, occasionally there were moments of "dead air time" when the computer was involved in a large database transaction or the speech recognizer was parsing a complex phrase. Here, it might have helped to provide additional audible feedback so the user knew when the computer was busy, similar to displaying an hourglass cursor on the computer monitor when a program is busy. This is not always easy to do. For instance, a software application can only determine when a recognizer event ended, not when it began, which makes it difficult to know when to transmit a busy signal.
As testing of the prototype progressed, it was concluded that prohibiting all visual feedback was too restrictive. Audible feedback is at least 10 times slower than reading, which limits the amount of information that can be given to the user. Most of the time, data entry would progress with audible feedback alone. There will, however, be times when the user would be better served by looking up at a monitor to evaluate the state of the system, especially during error detection and resolution.
A prototype voice-driven data collection system for histopathology data using only voice input and computer-generated voice responses was developed and tested. Under controlled conditions, the overall accuracy rate was 97%. Additional work is needed to minimize training requirements and improve audible feedback. It was concluded that this architecture could be considered a viable alternative for data collection in animal toxicology studies with reasonable recognition accuracy. Two papers were published based on this work in Computers in Biology and Medicine [Grasso and Grasso 1994] and M.D. Computing [Grasso 1995].